The power of chatgpt we have seen, as long as the input of the appropriate prompt, it can
write articles, write code, write poetry, can help us realize a lot of automated things, but the seed
of chatgpt, in 2013 Thomas Mikolov and others proposed Word2vec model is already buried, it is
because there is a word2vec foundation, there is a deep learning-based natural processing
processing take off in more than a decade, only later attention, gpt1, gpt2, gpt3, chatgpt, I'm ready
to start from word2vec, write a principle of attention and chatgpt, trying to make it easy to
understand, so that people without mathematical foundation can also understand. I'm going to
start with word2vec and write about the principles of attention and chatgpt.
Basic assumptions of word2vec
There are two basic assumptions underlying wordword2vec.
- Distributed semantics assumes that the semantics of a word can be described by
multiple variables, and each dimension of a word vector represents a semantic
component of the word. Each dimension of a word vector represents a semantic
component of a word. The word vectors as a whole can express the complete semantics
of a word. - Contextual semantics assumption: the semantics of a word can be described by its
contextual words. That is, the word vector representation of a word should be able to
Predict the contextual words around the word.
The so-called distributed semantic assumption is that a word, such as me, can be represented
by a vector$[0.1,0.2,0.4]$ the so-called morning and afternoon semantic assumption is that I eat
an apple in the afternoon and I eat an orange in the afternoon, because apples and oranges are
connected to the same context. They are both eaten in the afternoon, so they should both have
the same meaning.
neural network
Let's take an example of what a neural network is. In the simplest case, a neural network is a two-
dimensional equation
w1*x1+w2*x2+b=1w3*x1+w4*x2+b=1The so-called weights of the neural network, which are the vectors representing a word in
word2vec, are actually these w1,w2,w3,w4.
\begin{pmatrix} w1 & w2 \\ w3 & w4 \end{pmatrix} \quadSimple neural networks are usually used for binary classification, given a set of points,
placed in this set of weights, after the two-bit equation into the sigmoid function, you can achieve the purpose of categorization, the effect of categorization is like this
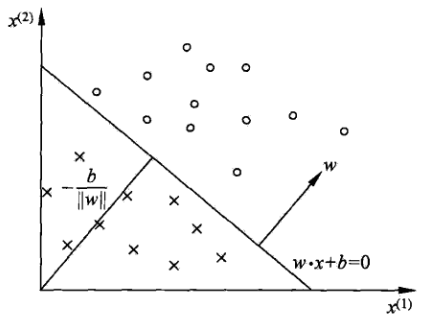
A diagonal line in the figure shows the dot above and x below.
word2vec is a use of neural networks in natural language processing
The word2vec process
word2vec consists of the following main steps.
- Constructing a text corpus:Collecting a large amount of text data as a training corpus for the
model. - Data preprocessing: the training corpus is preprocessed with word splitting, cleaning and
other preprocessing to get clean text data. - Constructing vocabulary lists: extract all the words from the preprocessed training corpus
and construct vocabulary lists. - Train word2vec model: use continuous bag-of-words or skip-gram model to train
feature vectors for all words in the vocabulary list based on the training corpus. - Get word vectors: after training, each word will correspond to a word vector, stored in the
vector space. - Evaluating word vectors: Evaluate the quality of word vectors by using their
performance in downstream tasks, or by using simulated reasoning with word vectors. - Save word vectors: Save the obtained words and the corresponding vectors for loading in
subsequent tasks. - Applied word vectors: pre-trained word vectors are applied to downstream natural
language processing tasks, such as text categorization and sentence similarity
computation, to improve the model performance.
What are the parts of word2vec?
word2vec consists of the following main components.
- Input layer: represents the input words. It can be the one-hot vector of the center word, or
the one-hot vector of the context word, according to the
CBOW and skip-gram distinction. - Projection layer: maps the high-dimensional one-hot representation of the input layer
to a low-dimensional dense word vector (word embedding). The word vector matrix
learned by this layer is the training result of word2vec. - Output layer: predict the output word corresponding to the word vector. Based on the input
word vector, calculate the probability of its context word or center word. - Loss function: compares the output layer results with the true label, usually using
classification evaluation metrics. For example, cross entropy is used to calculate how good
or bad the prediction is. - Optimization algorithms: use the feedback of the loss function to update the model
parameters. The common ones are gradient descent, Adam and other algorithms. - Training process: construct a large number of word training data, repeat the process of
forward propagation, loss calculation and back propagation, and iterate for many rounds
until the word vector matrix converges to obtain the optimal слов vector expression.
Therefore, it mainly consists of input and output expressions, word vector projection layer,
loss function and optimization process, and the word vectors are obtained through overall joint
training.
What is a word vector
To give a concrete example of input layer vectors in word2vec:.
Suppose a text sequence: "the cat sat on the mat".Construct a training data set: Center word: cat Context words: the, sat, on, mat Then.The input layer vector is the one-hot vector representing the center word "cat",which is used to propagate to the later projection layer. In the example, the vocabulary list is {the, cat, sat, on, mat}, so the one-hot vector of the centerword cat is.$[0, 1, 0, 0, 0]$ The length is the size of the vocabulary (5), and the position of the index corresponding to the center word "cat" is 1, while the others are all 0. This represents the one-hot input vector for the word cat, which is fed into the projection layer and propagated to train the network model. So the input layer vector is the vector representation of the input samples converted into a vector,based on which the neural network will be trained later.
What is the Projection layer?
The projection layer is an important part of the word2vec model. Its role is to.The one-hot representation of the input word vectors is mapped into a low-dimensional dense word embedding space. A concrete example is given here.Suppose the one-hot representation of the input word "apple" is:
$[0,0,0,0,1,0,0,0,0,0]$ (the vocabulary size is 8). Then the projectionlayer will map it to a low-dimensional word vector, such as a word vector of dimension 5: [0.1, 0.4, 0.5, 0.2, 0.3]$ The matrix parameters in the Projection layer are learned through model training, which can automatically obtain a low-dimensional word vector representation that is valid for the current task.This low-dimensional dense word vector represents the semantic information of the input words. The entire matrix of word vectors learned in the projection layer is the result of word2ve model training, i.e., word embedding.Therefore, the projection layer provides the mapping function for the input layer to get the semantic feature word vector, which is the core meaning of word2vec.
What is the output layer
In word2vec,the output layer matrix represents the result of predicting the center word context
word. Specifically, each element of the output layer matrix represents the probability that the model
predicts each word in the vocabulary as a context word for the current input word.
Example.
Assuming a vocabulary size of 5, the output layer matrix is a 1x5 vector: [0.1, 0.2, 0.1, 0.3, 0.3].
It denotes: the probability of word 1 as a context word in the first dimension is 0.1 the probability of word 2 as a context word in the second dimension is 0.2 ...
In the training process, the output layer matrix is compared with the actual context word distribution, and the loss function is calculated. And the parameters are gradually adjusted by backpropagation to make the prediction probability as close as possible to the real context distribution.
Therefore, the output layer matrix represents the prediction result of the context words,
calculates the logical relationship between the center word and the context words, and guides the
model to adjust the parameters to obtain the mastery of the semantic information. The so-called
actual context can be simply understood as the prediction of the next word according to the
previous word, the previous word may be $[0,1,0,0,0]$. The next word may be $[1,0,0,0,0]$
, the so-called calculation, can be simply understood as the previous word multiplied by the projection
layer and the next word subtracted.
How are the three connected?
The input layer, projection layer and output layer in word2vec are connected by forward
propagation and back propagation to realize the learning of word vectors.
Exercise.
-
Input layer to Projection layer: the one-hot vectors in the input layer are mapped to
the Projection layer by the weight matrix to get the word vectors. -
Projection layer to Output layer: Projection layer word vectors are used to calculate the
probability of each word in the output layer as a context through the weight matrix. -
Output Layer to Projection Layer: Compare the output probability with the real context,
propagate the gradient signal, and adjust the word vectors in the Projection Layer. -
Projection layer to input layer: Optimized word vectors, in turn, improve the discrimination of
input onehot words.
Through this closed-loop sequential connection, signals are propagated among the input,
projection and output layers t o optimize the adjustment of word vectors.
The encoding of semantic information is progressively improved to obtain a vector space
representation of the relationship between words and inter-words.
It can be seen that the three interact with each other through forward and backpropagation to
jointly learn the semantic representation in the word sense prediction task and obtain the word
vector word embedding.
A concrete example is used to illustrate how the input, projection and output
layers in word2vec are connected: suppose the input vocabulary list is: [a, b, c],
and the word vector size is 2Input layer: onehot=
[1,0,0]for a- Projection layer (word vector matrix): a word vector =
[0.1, 0.2], b word vector =[0.3, 0.4]c
word vector =
[0.5, 0.6]- Output layer (predicted probs): a context prob=
[0.7,0.2,0.1]indicates that a has the highest probability of appearing to the left of b - Through the output layer error, assuming that the next word is pencil and the onehot
vector is
[1,0,0]adjust the a word vector in the Projection layer and re-predict. The new a
vector is adjusted to predict more accurately to b as the contextual environment.- The new a-word vector in turn acts on the representation of the onehot vector a. Enhancing the model's understanding of a.
In this way, the optimization of the word vector matrix in the projection layer is achieved
through continuous backward and forward propagation of signals, so that the word vectors are
better modeled for contextual semantic correlation.
This illustrates the process of connecting the three levels and realizing the learning of word
vectors by interacting with each other. - Projection layer (word vector matrix): a word vector =
How Google determines that two keywords are similar
Now we have the word vectors generated by word2vec, suppose the word vectors for
jasmine and honeysuckle are [0.1,0.2,0.3], [0.11,0.22,0.31] respectively. We just need to
compute their Euclidean distance,\sqrt{(0.11-0.1)^{2} + (0.2-0.21)^{2} + (0.31-0.3)^{2}}
, the You don't have to do the math to know that it's a very small value. If it's another keyword,
honeysuckle and automobile, their Euclidean distance is very large, of course there are other
distances, such as the cosine distance, but the difference will be very large for different classes
and very small for the same class.